How Solaris is powering market-beating financial products with decentralized data management
4 minute read






Data is often called "the new oil", but the comparison isn't exactly accurate.
Yes, data, like oil, is extremely valuable. But where oil is a finite, increasingly scarce resource, the amount of data the average organization has access to is growing at an exponential rate.
In 2020, there were 64.2 zettabytes of data — that's 642 and 20 zeroes. And, by 2025, its estimated data will balloon even further in volume, reaching a staggering 180 zettabytes.
Yet, despite the unimaginably huge amounts of valuable data being created daily, most organizations aren't taking full advantage of what they have at their disposal.
At Solaris, data has been a fundamental part of the way we operate from day one. So, after becoming the first German bank to migrate fully to the cloud in November 2020, we've taken the further step of partnering with the Data Cloud company Snowflake to create a powerful, flexible, and scalable data platform that can help us push our products to the next level.
Here's what this means for us and our partners moving forward.
The pitfalls of centralization
While every organization has its unique data challenges, these often boil down to three fundamental issues: the data is fragmented, siloed, and hard to access.
The typical financial services firm is drowning in data from multiple sources: credit bureaus, KYC information, transaction data, risk management reports...the list is endless.
This data is spread across different departments and stored in inconsistent formats — including word documents and spreadsheets that have to be manually organized and updated. As a result, it can sometimes be difficult to track down the data you need, or even take stock of how much data you have.
Many organizations address this issue by using data lakes and data warehouses.
Just as, in nature, lakes provide the surrounding ecosystem with a single, easily accessible source of water, data lakes collect every byte of raw data that enters your organization in one place.
Once the data is processed and transformed — that is verified, organized, and made fit for consumption — it's stored in a data warehouse, so anyone in the organization can quickly find what they need, when they need it.
Data lakes and data warehouses create a single source of truth: a centralized repository of all data within the organization.
But while centralizing data management has the advantage of improving accuracy and making it easier for everyone in the organization to find and access the data they need, it also has a critical flaw: it creates a single point of failure.
If a team changes one piece of data, this could have implications for every other department that relies on that data, even if indirectly.
More to the point, as the sources, volume, and complexity of data increase — and this will inevitably happen over time — managing everything in one place creates a bottleneck that makes the organization less instead of more flexible.
So how can organizations manage data in a way that enables teams to be agile and adaptable, but also prevents silos?
From data mess to data mesh
At Solaris, we've solved this issue by using an analytical architecture and operating model known as a data mesh.
A data mesh uses a domain-oriented, decentralized approach to organizing data. In other words, instead of gathering everything in one large, company-wide data warehouse, analytical data is organized by a particular use case, process, or sphere of activity and owned by the team that is most reliant on it.
Case in point, you could gather all the data required for regulatory reporting in a 'compliance' domain, while the data related to a given product is grouped in its own separate domain.
Organizing data in this manner enables different teams to get quick, direct access to the data they need while keeping things manageable. Where a single data warehouse forces a one-size-fits-all approach, with data mesh architecture it's easier to make changes without affecting the data other teams need to work with.
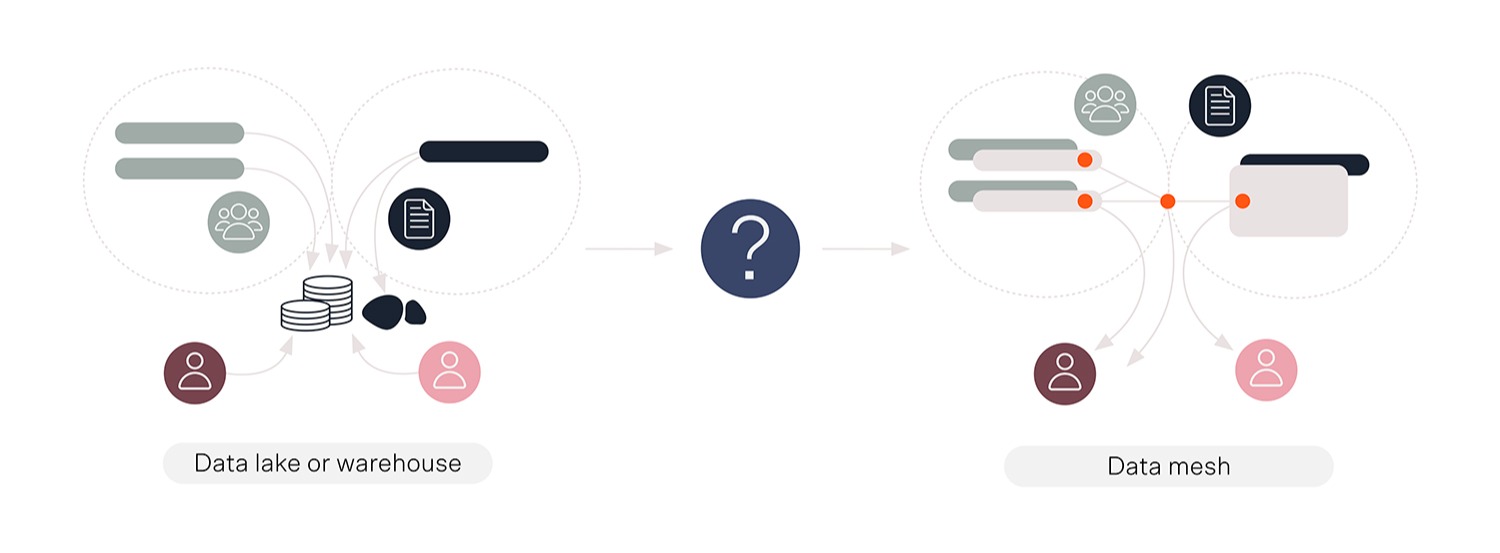
At the same time, because every domain lives on the same centralized, self-service infrastructure and governance is standardized, there's no unnecessary fragmentation. Different domains can exist in parallel and connect where it makes sense, so that anyone can easily access the data they need in a format they can understand.
Most importantly, data mesh architecture is much more scalable than a centralized repository. Because data is organized by domain and managed in a decentralized manner, the volume of data never becomes unwieldy. And this means there's less risk of bottlenecks and fewer data quality issues.
Powering next-generation financial services products, with Solaris
The data management platform we've created in partnership with Snowflake — which we've chosen because of how easy it is to build custom data domains at scale right out of the box — has transformed how we interact with stakeholders both inside and outside our organization.
Treating data as a product and organizing it by domain has empowered our tech, operations, and audit teams, enabling them to get closer to the data they use on a day-to-day basis and use in-depth, data-backed insights to inform every step of their decision-making.
More importantly, the new model has enhanced our data mining capabilities and made us more flexible and adaptable.
We're now able to gain a more granular understanding of how our partners and their end-customers use our products, identify gaps in functionality, and use this data to inform our approach to updates and development roadmaps.
In the coming years, we're also hoping to make both front-end and back-end data available to our partners so they can use it to inform their own decisions, too.
Data shouldn't be a "black box"
In this day and age, not having access to the right data is like navigating an unfamiliar city without your Maps app. Chances are you'll get lost. And, in business, that could prove extremely costly in many ways.
Data is essential for decision-making, planning, forecasting, and compliance.
More importantly, it's critical for creating products that truly address customers' most pressing needs and keep them coming back.
By fostering a data self-service platform mentality and using state of the art tools like Snowflake, Airflow, and Tableau, our goal is to facilitate quick, easy access to useful insights that will help our stakeholders build tailor-made products that do just that.





